
Plus de 800 fiches pratiques pour les managers, sans pub et sans traceurs…

- ▶ Management de l'entreprise ▶ Management Démocratique
- Conception de la stratégie
- Principes de gouvernance
- La Performance des métier
- Le contrôle de gestion
- ▶ Innover en équipe
- L'Innovation et la Performance
- L'Innovation Managériale
- La Méthode SOCRIDE
- ▶ Décider au quotidien
- Le processus de Décision
- La Décision en équipe
- Les Techniques de décision
- ▶ Guide gratuit de l'Autoformation
- Méthode d'autoformation
- Les 7 Qualités pour réussir
- Comment s'auto-évaluer ?
- ▶ Formation Gratuite Management
- Formation tableau de bord et BI
- Formation Management de Projet
- Formation Entrepreneuriat
- ▶ ebook et PDF management gratuits
- ▶ PDF Entrepreneuriat
- ▶ ebook Perfonomique


 PDF Management
PDF Management 
Les bases de données relationnelles, SGBDR
Définition SGBD, la gestion des données de l'entreprise
Un système de base de données, SGBD, est un logiciel spécialisé dans la gestion des données de l'entreprise indépendamment des programmes qui les utilisent.Les SGBD isolent physiquement les données de référence des applications qui les utilisent. Plus particulièrement, les SGBD relationnels placent en évidence les relations existantes entre les différentes données de l’entreprise.
Du SGBD au SGBDR, l'historique
Avant l'invention des bases de données relationnelles, les informaticiens utilisaient d'autres types de bases de données moins pratiques telles que les bases hiérarchiques et les bases réseaux.Au début des années 70, Edgar Frank Codd, alors chercheur au sein d'un laboratoire IBM, a mis au point un modèle révolutionnaire centré sur la mise en relation des données. Le SGBDR, R pour relationnel, était né. IBM ne s'est pas intéressé aux travaux de l'équipe du Dr Codd, au contraire de Larry Ellison qui a créé la société Oracle Corp dans la foulée pour développer et exploiter ce nouveau SGBD avec le succès que l'on connaît.
Définition : base de données relationnelle
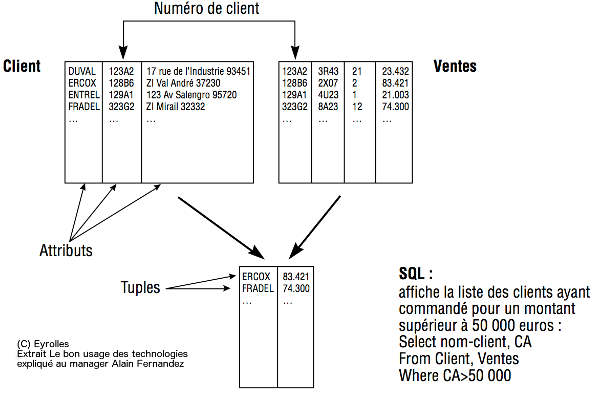
Les SGBD relationnels mettent au premier plan les relations entre les données. Celles-ci sont organisées en tables à deux dimensions. On parle alors de ligne et de colonnes.Considérons une table client, voir la figure ci-dessous. Un enregistrement tel que la description des données d'un client spécifique correspond à une ligne. Chaque colonne correspond à un attribut spécifique : le nom, l'adresse, le téléphone...
Ainsi, il est particulièrement aisé pour un programme ou directement pour un utilisateur d'accéder à un client précis ou de trier, ou d'extraire les enregistrements clients selon une caractéristique, un attribut donc.
À quoi sert une base de données ?
Les différents services de l'entreprise, du commercial à la comptabilité en passant par la production et le marketing pour ne citer que ceux-ci, exploitent les mêmes données. Dans les temps immémoriaux, en tout cas à l'échelle des systèmes d'information, chaque application utilisait ses propres données.On imagine aisément les erreurs dues à cette multiple redondance, notamment dès que l'on commence à effectuer des mises à jour de données de références comme les informations clients ou les fiches produits. À quel moment est-on certain d'avoir mis à jour tous les applicatifs et cela sans erreur de saisie ? Jamais.
C'est là le rôle incontournable des systèmes de bases de données, relationnelles de préférence. Toutes les données existent en un point unique, et les applications comme les utilisateurs n'utilisent que cette unique source. Ils accèdent aux données grâce à un langage dédié dit de 4ème génération : SQL pour Structured Query Language.
Principe : Le relationnel, comment ça marche ?
Un SGBD relationnel organise les différentes données sous forme de tables. Chaque table est structurée en lignes et colonnes. Toutes les tables de la base de données peuvent être simplement rapprochées dès qu’elles partagent une même colonne (un attribut). Par exemple, la table « client » contient toutes les coordonnées des clients et la table « ventes » regroupe les différents achats réalisés par les clients.Chacune des deux tables a une colonne commune : le numéro du client. Il sera possible de réaliser une jointure simple pour, par exemple, définir le chiffre d’affaires par client, éditer la liste des clients ayant commandé pour plus de 50 000 euros dans le mois, ou encore connaître les produits vendus par région. Pour cela, on utilise un langage standardisé d’interrogation des bases de données : SQL, voir la figure ci-dessus.
La définition des tables de référence ne saurait être arbitraire. Il est important de structurer l’ensemble de la base de données pour pouvoir répondre à un maximum de requêtes correspondant aux besoins de l’entreprise, en ne réalisant que des jointures simples.
Pour mieux maîtriser la conception du schéma relationnel, il existe une normalisation : les formes normales (NFN). Ces dernières définissent trois niveaux de règles pour éviter les erreurs de conception, comme les redondances mal à propos pénalisant les évolutions futures de la base.
- Une requête est une commande envoyée vers le SGBD pour rechercher, écrire ou lire des données de la base.
- Le schéma relationnel décrit les tables et leurs relations.
Associer traitements et données
Lorsque l’on analyse les applications utilisant les mêmes données, on constate la présence de traitements similaires. En fait, la logique de ces traitements est étroitement liée aux données, indépendamment des applications. Ils pourraient exister en un seul exemplaire partagé par l’ensemble des applicatifs, comme les données communes.Les SGBD modernes offrent la possibilité de placer directement les traitements partagés au niveau de la gestion de la base. Étudions les "triggers" et les "procédures stockées".
Triggers ou déclencheurs
Ce sont des traitements automatiques qui se déclenchent sur un événement précis. Par exemple, lorsqu’un certain enregistrement de la base est mis à jour, un déclencheur lance automatiquement un programme de contrôle de validité ou de mise à jour de champs associés.Procédures stockées
Ce sont des traitements stockés dans la base de données. Les procédures stockées sont habituellement exécutées sur demande d’un poste client. Elles simplifient et rationalisent la programmation en centralisant les traitements communs.Gestion de la cohérence de la base
Le maintien de la cohérence de la base de données est un impératif de survie pour le système d’information. La base de données ne doit jamais se trouver dans une état instable. Il est préférable d’utiliser un ensemble de données moins fraîches mais cohérentes plutôt que partiellement mises à jour et totalement illogiques. La cohérence de la base de données peut à tout moment être mise en péril. Pour éviter toute incohérence, les systèmes de gestion de données intègrent différents services. Ètudions le verrouillage.Verrouillage
Pour éviter les conflits d’accès sur une même ressource, les systèmes de SGBD intègrent des fonctions de verrouillage.Prenons un exemple :
1) Une tâche commence à écrire une liste de données.
2) À tout moment, elle peut être interrompue par une autre tâche plus prioritaire.
3) La liste partiellement modifiée est alors incohérente.
4) Elle est pourtant accessible et utilisable par des tâches plus prioritaires ! On imagine sans mal les erreurs possibles.
Avec le principe du verrouillage, la première tâche commencera par poser un verrou. Les données seront inaccessibles, tant que la même tâche n’aura pas levé le verrou.
Avec le principe du verrou, on est sûr que la cohérence de la base ne sera pas mise en péril par des accès intempestifs aux données en cours de modification. La cohérence est un principe fondamental des bases de données.
Deadlock (interblocage)
C’est une situation typique de la programmation multitâches :1) Une tâche T1 a verrouillé pour son usage une ressource A, et attend le déblocage d’une ressource B avant de poursuivre son exécution.
2) Cette ressource B est elle-même bloquée par une tâche T2 qui attend justement la libération de A avant de poursuivre son exécution.
3) Le système est dit interbloqué, chacune des tâches s’attendant mutuellement. Il est en situation de verrou mortel (deadlock). Dans un tel cas, la seule solution est de détruire une des deux tâches (les systèmes évolués prennent en charge cette gestion).
Les SGBD modernes proposent de regrouper l’ensemble des requêtes d’un même lot en une unité insécable : la "transaction"...
Transaction
Il est possible de réunir plusieurs requêtes liées dans la même unité de traitement : la transaction. Le système garantira alors l’exécution de la transaction complète. S’il ne peut la traiter en totalité, il reviendra à l’état stable antérieur. Il n’y aura pas d’exécution partielle non maîtrisée.Prenons le cas d’une opération bancaire de débit/crédit. Pour conserver la cohérence de la base, la requête créditant le compte du client A et la requête débitant le compte du client B doivent toutes les deux s’exécuter. Si jamais le système connaît une défaillance entre les deux requêtes, l’une des deux opérations, débit ou crédit, ne sera pas exécutée. La base de données deviendra incohérente.
En plaçant les deux requêtes dans une même transaction, nous aurons la garantie de l’exécution commune des deux opérations. En cas de défaillance du système, aucune des deux ne sera exécutée. La base est toujours cohérente.
Le Modèle "ACID" et la gestion des transactions
Le modèle ACID définit les règles des transactions pour garantir la cohérence de la base. C'est indispensable pour gérer les requêtes provenant de différentes applications. Une transaction permet justement d'envelopper plusieurs requêtes qui doivent impérativement s'exécuter séquentiellement en une même unité. Si jamais il s'avérait impossible de traiter la totalité de la transaction, le système revient à un état stable antérieur.- Atomicité : toutes les actions sont exécutées ou aucune.
- Cohérence : la transaction doit placer le système en un état cohérent. Si ce n’est pas possible, elle revient à l’état stable précédent.
- Isolation : les changements intermédiaires, apportés à la base par la transaction en cours, ne sont pas vus par les autres transactions exécutées en parallèle depuis d’autres tâches avant la validation.
- Durabilité : une fois validés, les changements apportés par la transaction sont durables.
Les systèmes de bases de données relationnels les plus couramment utilisés aujourd'hui
- MySQL, une référence des logiciels "libres" open source
- Oracle, la référence des SGBR Objet depuis la version 8
- SQL Server, un produit phare de la gamme Microsoft entreprise
- PostgreSQL, une solution libre de SGBD Objet
- Access, le produit SGBD Microsoft de la gamme Office
- IBM DB2, le produit de référence d'iBM en matière de SGBD
- Voir aussi pour les analyses rapides les solutions Les bases de données "In-Memory" où la BDD est stockée en mémoire vive.
 Instaurer la démocratie dans l'entreprise
Instaurer la démocratie dans l'entreprisePour en finir avec le mépris, principe délétère du management d'hier et d'aujourd'hui
Auteur : Alain Fernandez
Sujet : Expérience concrète d'instauration de la démocratie au sein d'une PME
Pages : 360 pages
Prix Format papier : 19,95 €
Prix Format ebook : 9,99 € (epub ou kindle) Librairies en ligne...
Dispo :

 Autres librairies en ligne...
Autres librairies en ligne... Présentation détaillée du livre "la transformation démocratique de l'entreprise"
Présentation détaillée du livre "la transformation démocratique de l'entreprise"
L’auteur
 Alain Fernandez est un spécialiste de la mesure de la performance et de l’aide à la décision. Au fil de ces vingt dernières années, il a conduit et accompagné de nombreux projets d'entreprise en France et à l'International. Il est l'auteur de plusieurs livres publiés aux Éditions Eyrolles consacrés à ce thème et connexes, vendus à plusieurs dizaines de milliers d'exemplaires et régulièrement réédités.
Alain Fernandez est un spécialiste de la mesure de la performance et de l’aide à la décision. Au fil de ces vingt dernières années, il a conduit et accompagné de nombreux projets d'entreprise en France et à l'International. Il est l'auteur de plusieurs livres publiés aux Éditions Eyrolles consacrés à ce thème et connexes, vendus à plusieurs dizaines de milliers d'exemplaires et régulièrement réédités. À ce sujet, voir aussi
À ce sujet, voir aussi
- Le Big Data a introduit une toute autre manière de gérer les données. Les bases de données relationnelles ne sont pas adaptées aux besoins du décisionnel et encore moins du Big Data. Les bases NoSql, comme leur intitulé ne le cache pas, rompent avec les principes des bases relationnelles, et notamment le concept ACID, pour faciliter le stockage en grande quantité et surtout la rapidité de traitement : Les bases NoSql.
 Qu'est-ce qu'un langage L4G ? (Langage de 4ème Génération)
Qu'est-ce qu'un langage L4G ? (Langage de 4ème Génération)
Qu'est-ce qu'un langage de 4ème génération ? En quoi est-il différent des autres langages, le cas de SQL.
Un langage pour communiquer... avec la "machine" Pour communiquer avec un système informatique et en extraire des données, nous utilisons des langages spécifiques. Ces langages ont évolué au fil du temps et il est coutumier de les classer par génération, selon le degré d'évolution et d'orientation utilisateur, depuis les langages machines jusqu'au... Le cloud computing pour le SI de l'entreprise
Le cloud computing pour le SI de l'entreprise
Exploiter le système d'information, stockage des données et traitements, en terme d'usage c'est ce que propose le cloud computing. C'est-à-dire plutôt que d'investir dans une infrastructure figée pour bâtir votre système d'information d'entreprise, il est peut être plus judicieux d'exploiter les capacités des réseaux pour louer des services à un fournisseur spécialisé et gagner ainsi en souplesse et en flexibilité. Au programme, une définition suivie d'un gros plan sur le SaaS et enfin pour finir un retour sur le principe du cloud computing expliqué en termes simples. Bases de données NoSQL, le principe
Bases de données NoSQL, le principe
Que sont les bases de données Non SQL ? Quelles sont les applications où elles s'avèrent plus performantes que les bases de données relationnelles SGBD-R ? Les bases de données relationnelles se prêtent mal aux exigences des applications massivement parallèles exploitant de grandes quantités de données. Les bases de données NoSQL (Not Only SQL) marquent une rupture assez brutale avec la manière MapReduce, définition
MapReduce, définition
MapReduce est un modèle de programmation massivement parallèle adapté au traitement de très grandes quantités de données. Les programmes adoptant ce modèle sont automatiquement parallélisés et exécutés sur des clusters (grappes) d'ordinateurs. MapReduce est un produit Google Corp. Hadoop, définition
Hadoop, définition
Hadoop est un projet Open Source géré par Apache Software Fundation basé sur le principe Map Reduce et Google File System, deux produits Google Corp. Le produit est écrit en langage Java. Le principe repose sur l'exécution du traitement répartie multi noeuds pour augmenter drastiquement les capacités de calculs et de stockage afin de traiter de très grandes quantités de données.
 À lire...
À lire...
 Bases de Données
Bases de Données
Concept, utilisation et développement
Jean-Luc Hainaut
Dunod
4ème édition 2018
736 pages
Dispo : www.amazon.fr &
Format Kindle
Les ouvrages de Georges Gardarin ont longtemps été la référence en matière de SGBD. Par chance celui-ci est proposé gratuitement en format Kindle, profitez-en !
 Bases de Données
Bases de Données
Georges Gardarin
Eyrolles
787 pages
Dispo : www.amazon.fr &
Format Kindle gratuit
Le livre de référence du site...
 Les nouveaux tableaux de bord des managers
Les nouveaux tableaux de bord des managers
Le projet Business Intelligence clés en main
Alain Fernandez
6ème édition Eyrolles
468 pages
Pour acheter ce livre :

Format ebook : PDF ou ePub, Kindle
 Piloter l'Entreprise Innovante...
Piloter l'Entreprise Innovante...
De l'importance de réformer les principes archaïques de contrôle de la mesure de la performance pour enfin dynamiser la prise de décision en équipe, incontournable clé de l'entreprise innovante. La méthode SOCRIDE centrée sur les questions de Confiance et de Reconnaissance est ici expliquée, illustrée et détaillée :
 Les tableaux de bord du manager innovant
Les tableaux de bord du manager innovant
Une démarche en 7 étapes pour faciliter la prise de décision en équipe
Alain Fernandez
Éditeur : Eyrolles
Pages : 320 pages
 Consultez la fiche technique »»»
Consultez la fiche technique »»»
Pour acheter ce livre :
Format ebook : PDF & ePub,
Format Kindle
Voir aussi...



 Partagez cet article...
Partagez cet article...





(total partages cumulés > 45)
Ouvrages du même auteur

Réformer le management

Décider en équipe

Tableau de bord DIY

Bonnes pratiques projet

Le système décisionnel
De salarié à entrepreneur

Astuces Entrepreneur

Ebook autoformation

PDF Management 




Les plus lus...
 1. Manager le Projet CRM
1. Manager le Projet CRMLe projet CRM est un projet complexe qui implique impérativement plusieurs fonctions et activités ...
2. Qu'est-ce que l'EAI ? Intégration et Urbanisation
3. Gestion de la connaissance : Le Knowledge management
